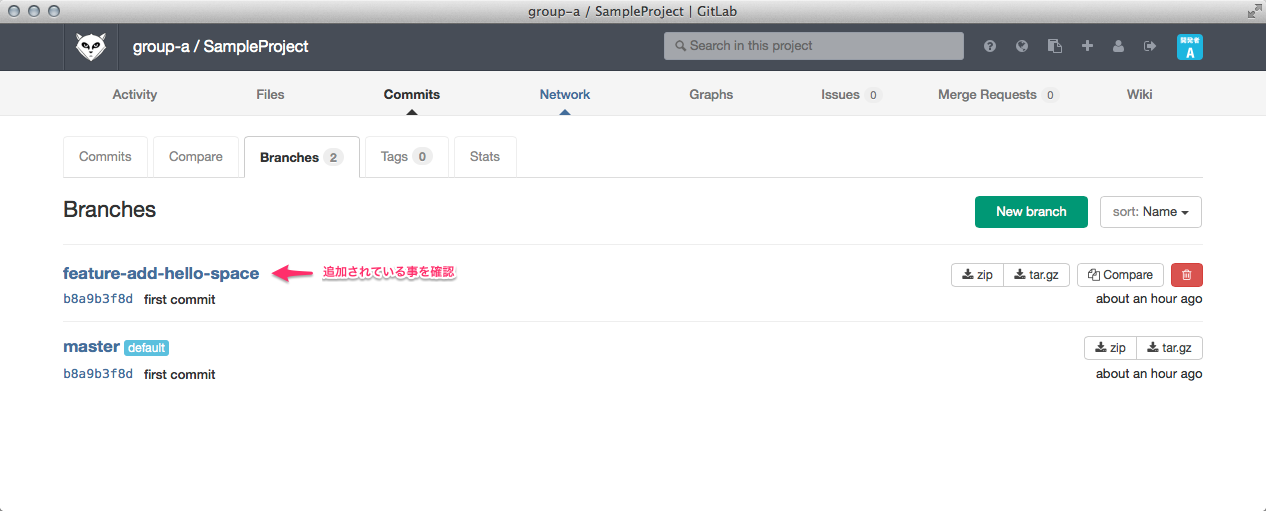
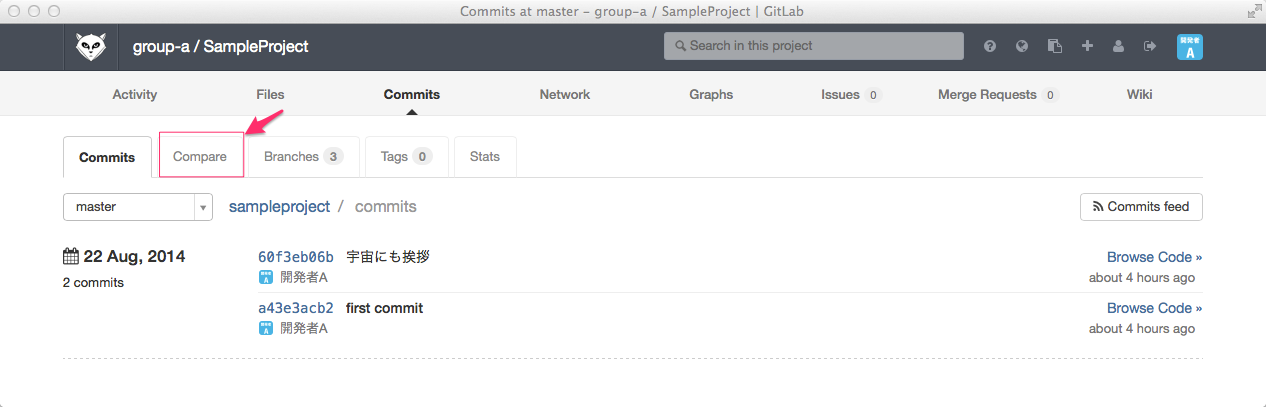
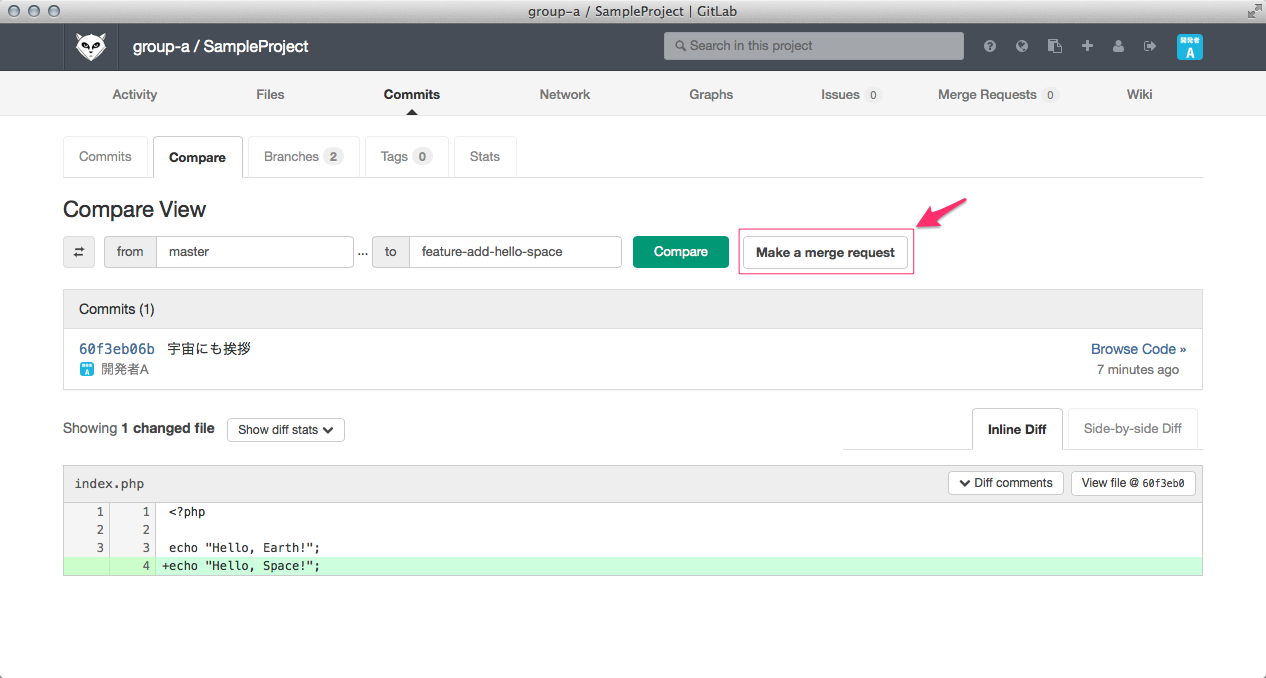
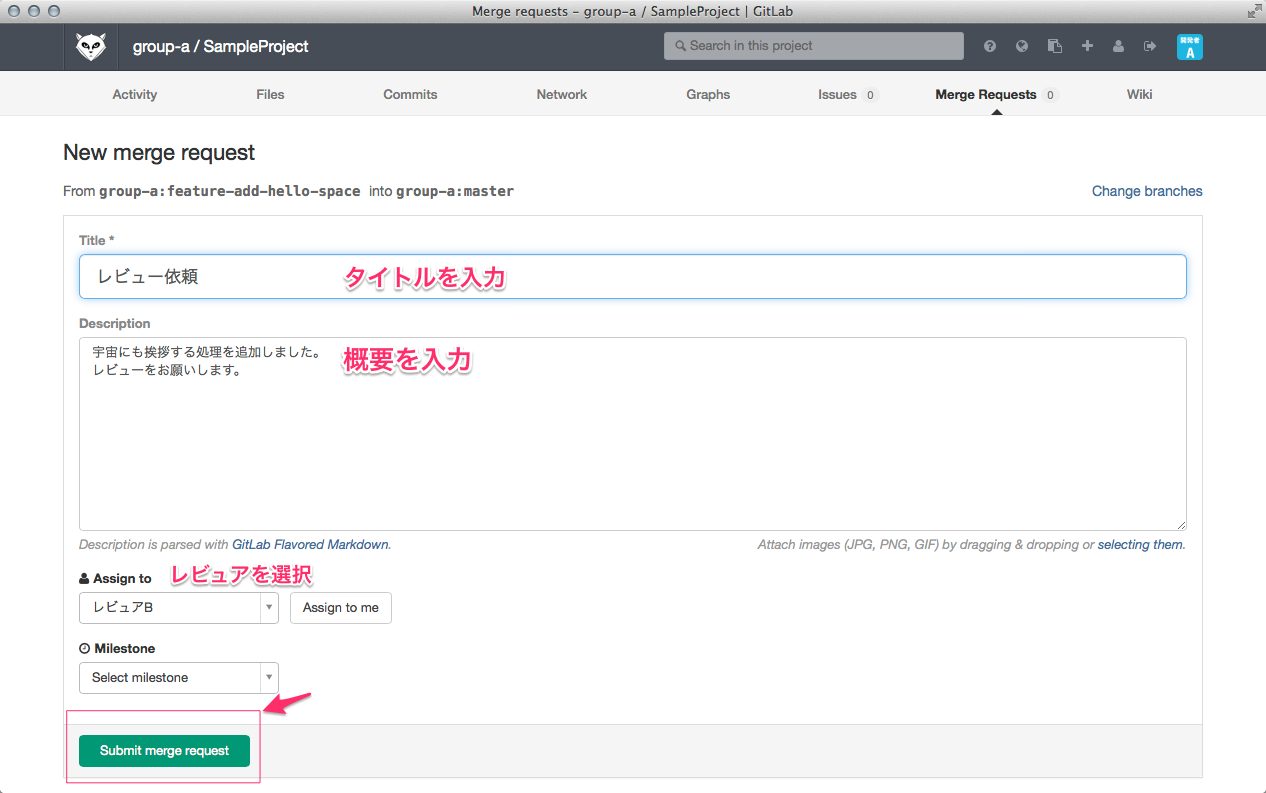
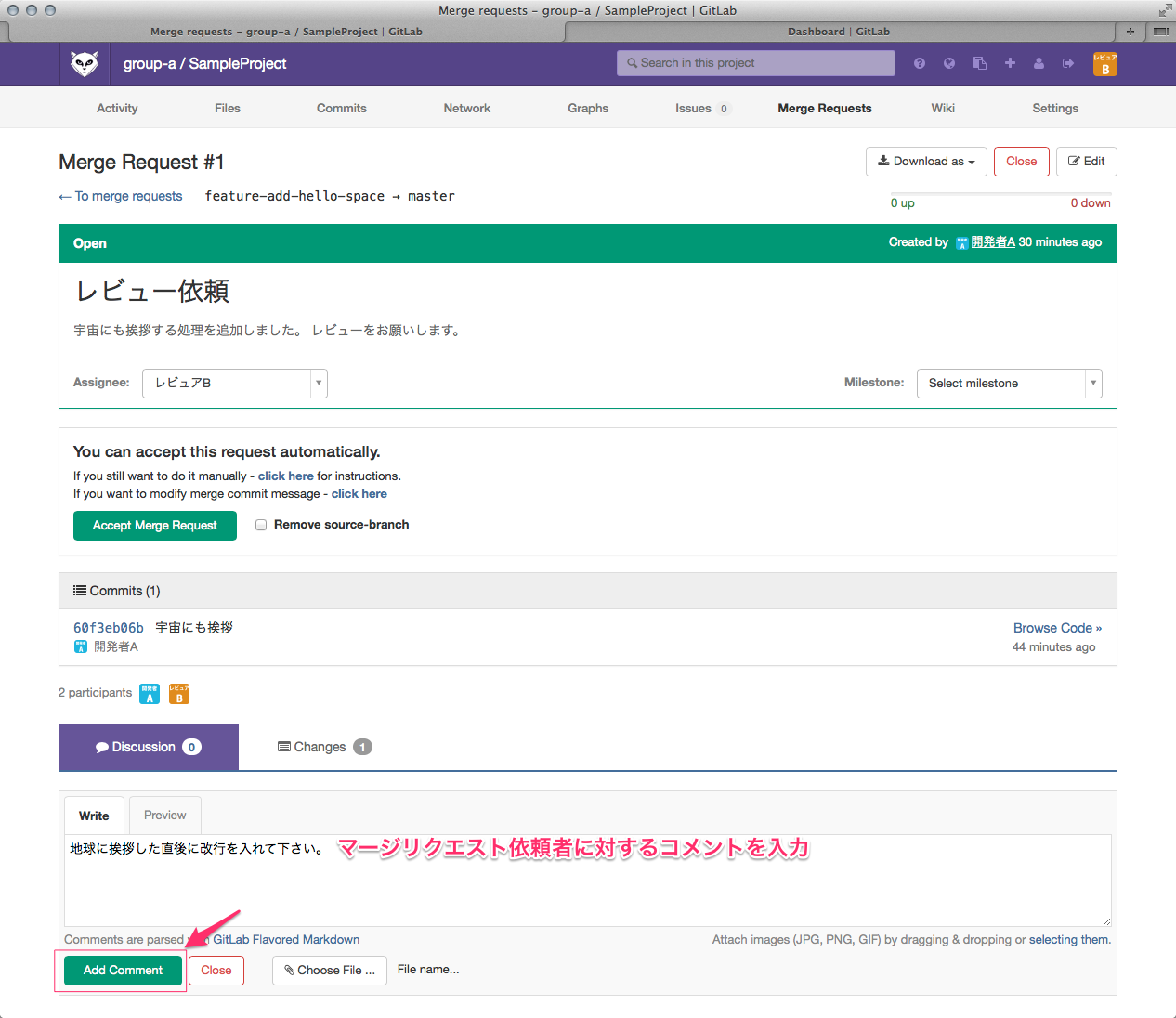
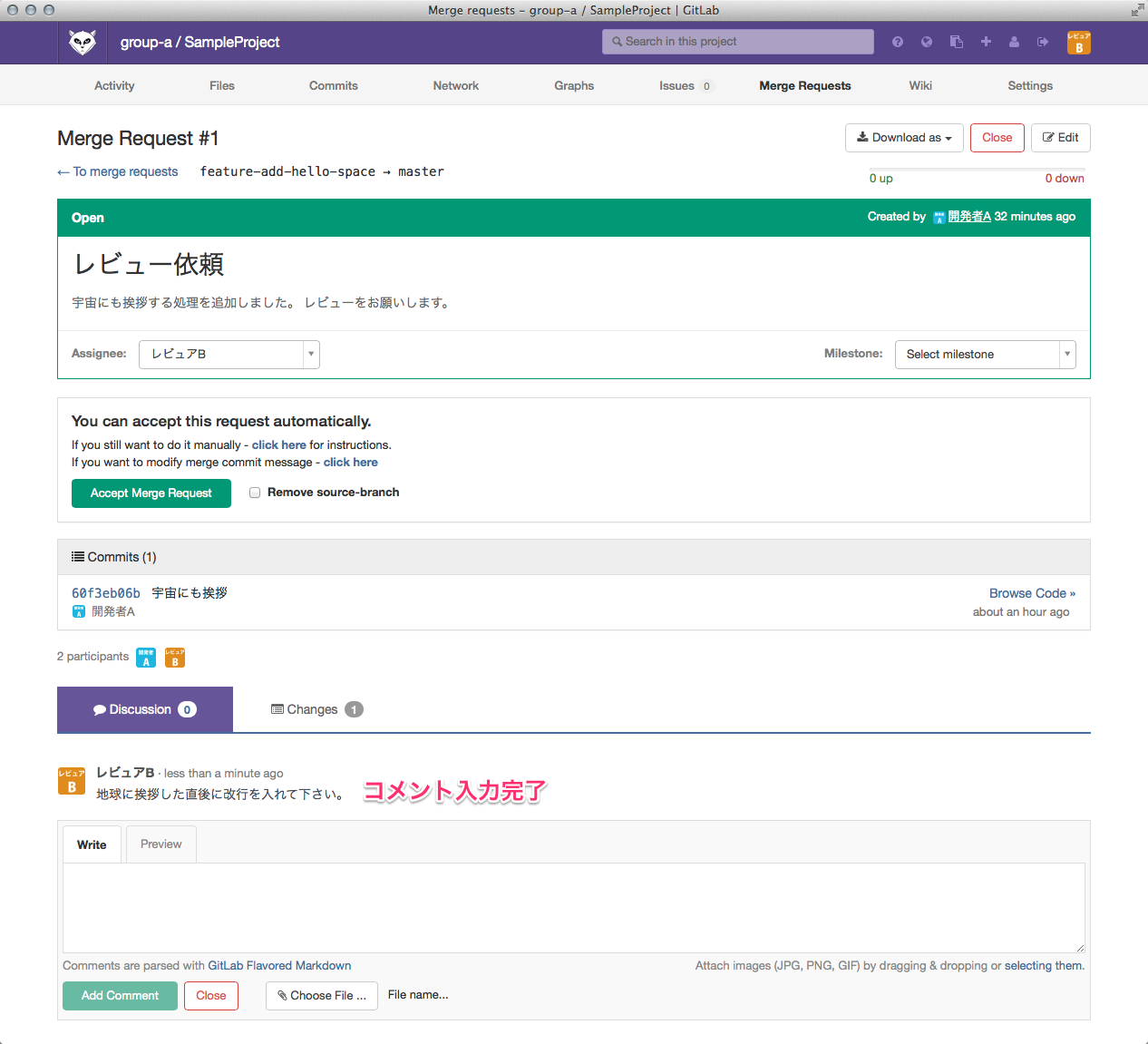
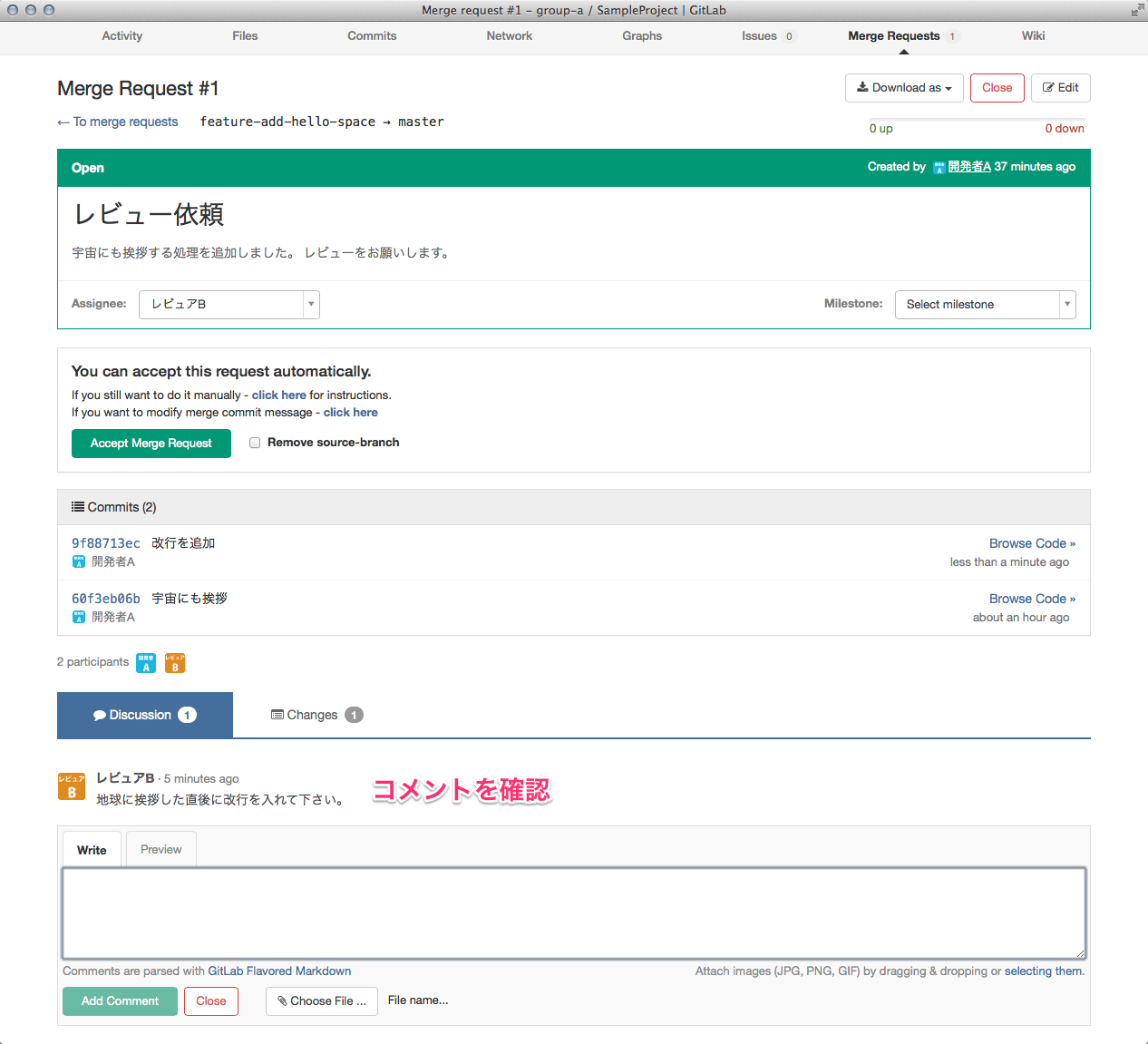
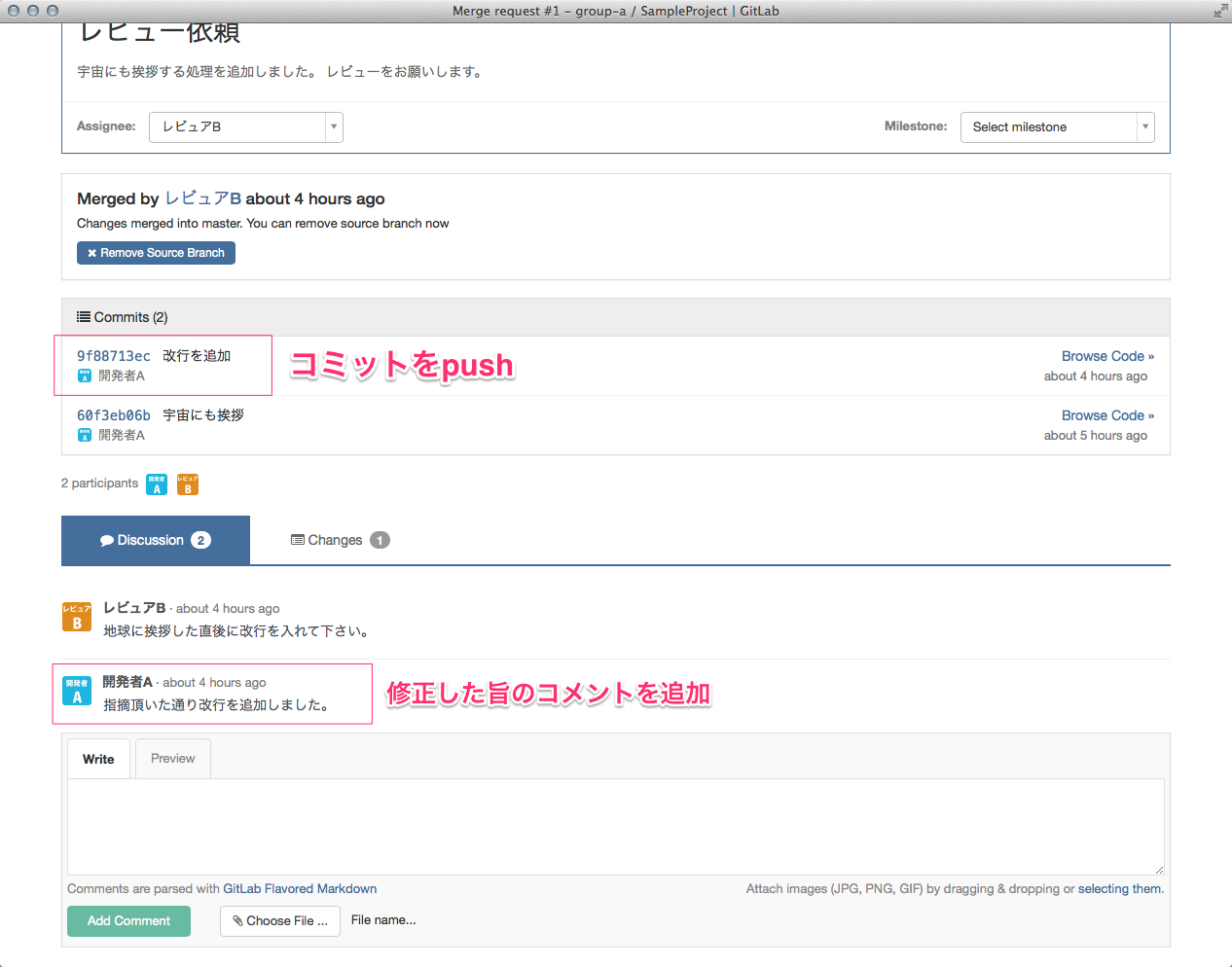
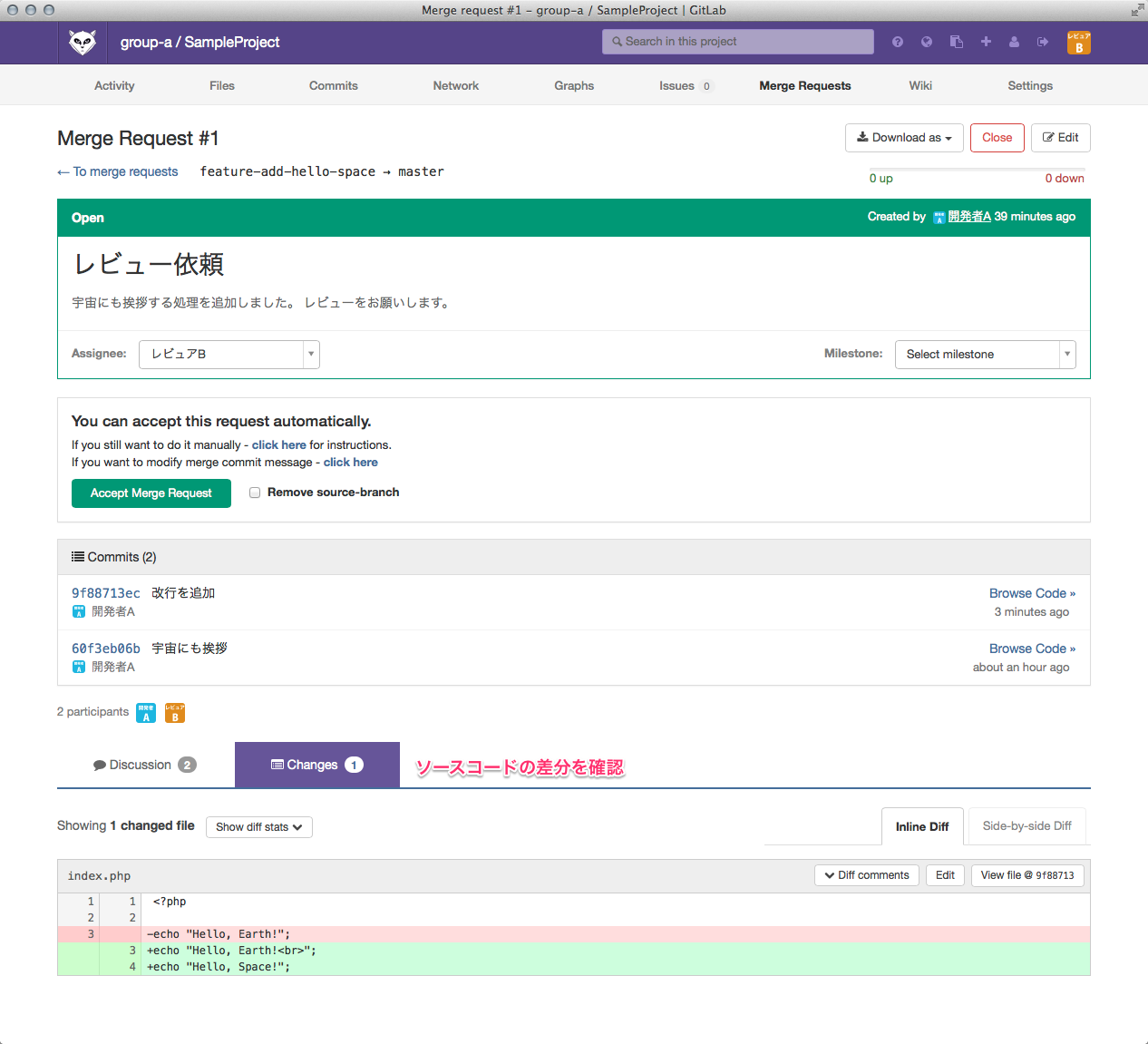
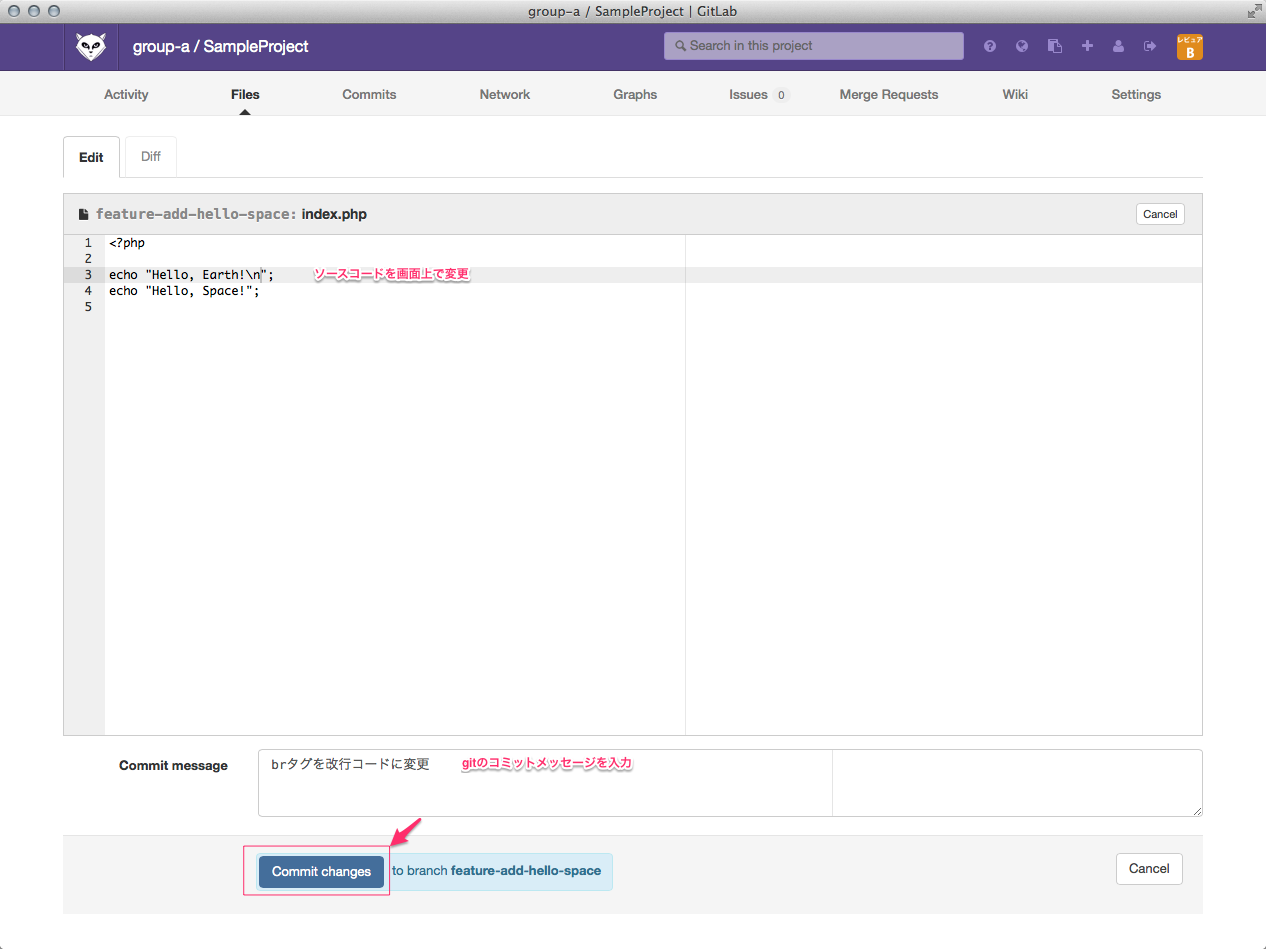
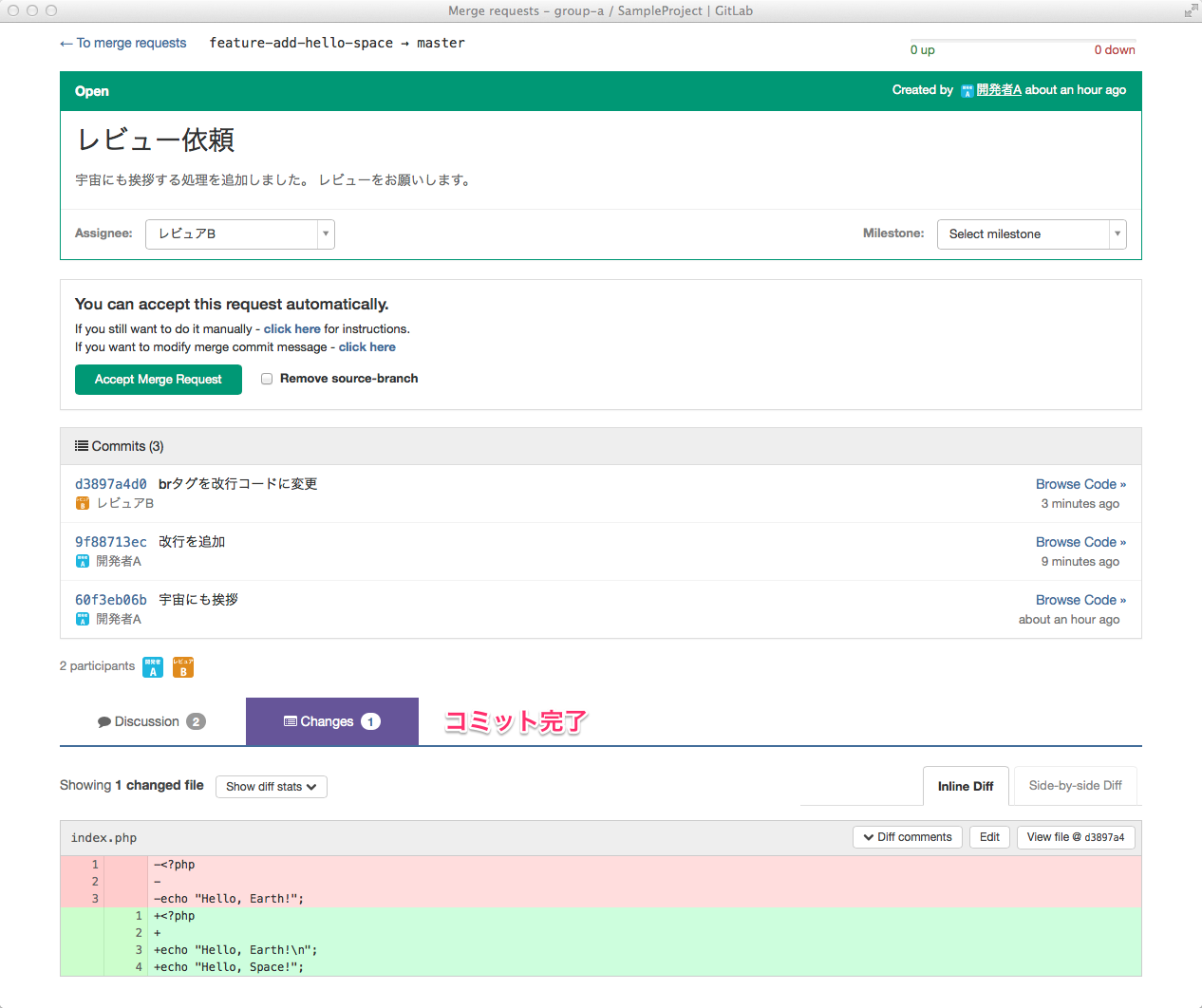
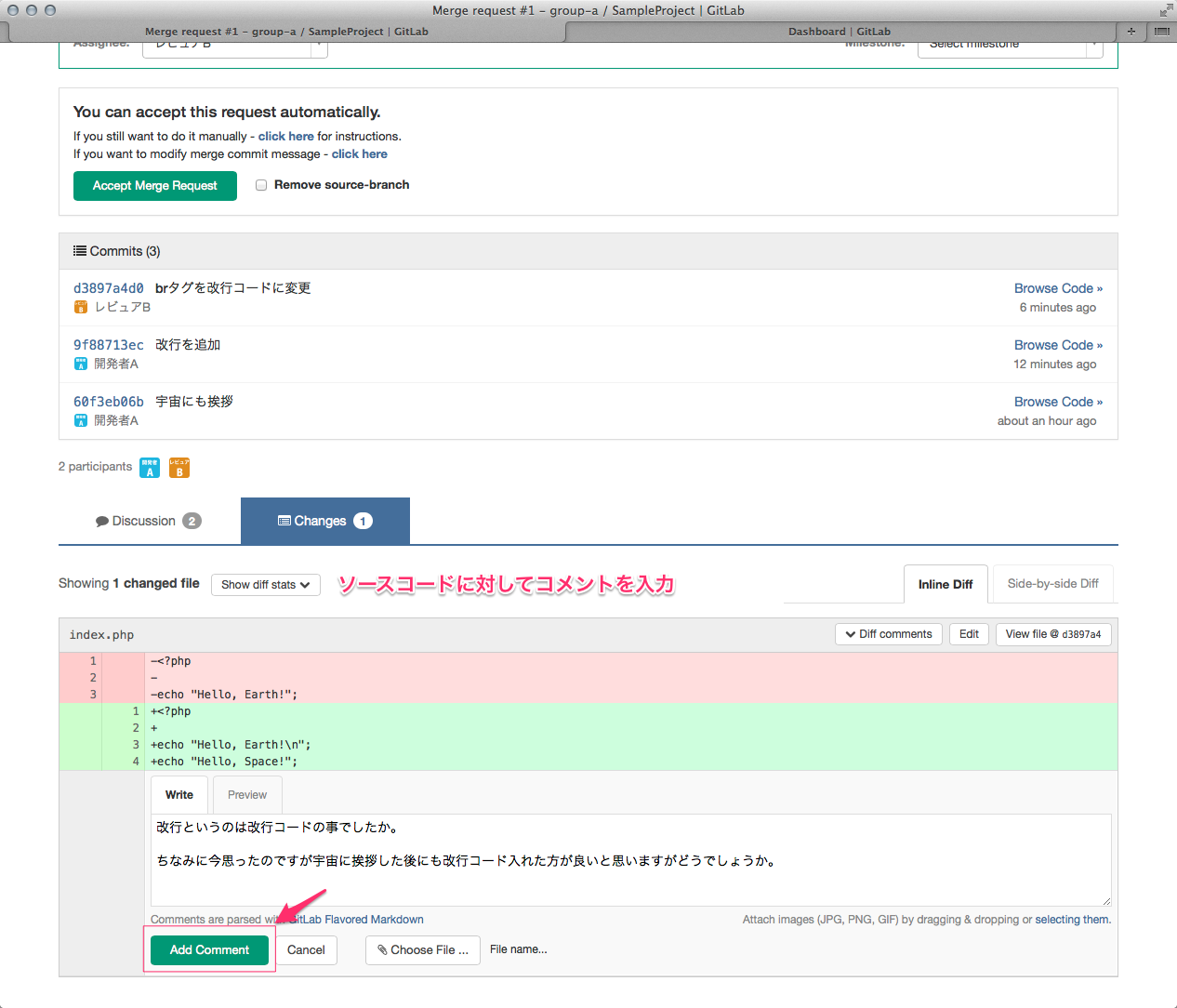
ひっさびさの いかお です。
前回の宣言通りつくってみました。
MJPEGで撮影できるUVCカメラで動画撮影し、とれた映像をそのまま書いたら
JPEGじゃね?
と思って作ってみますた
カメラはlogicoolのC920Tです。
多少不安定な感じだけど、あっさり認識した
[6734110.675010] usbhid 3-2:1.0: >couldn't find an input interrupt endpoint [6734110.675925] usbcore: registered new interface driver usbhid [6734110.675927] usbhid: USB HID core driver [6734966.300322] usb 3-1: >new high-speed USB device number 11 using xhci_hcd [6734966.319401] usb 3-1: >New USB device found, idVendor=046d, idProduct=082d [6734966.319405] usb 3-1: >New USB device strings: Mfr=0, Product=2, SerialNumber=1 [6734966.319408] usb 3-1: >Product: HD Pro Webcam C920 [6734966.319410] usb 3-1: >SerialNumber: A0313D6F [6734966.319925] uvcvideo: Found UVC 1.00 device HD Pro Webcam C920 (046d:082d) [6734966.320342] input: HD Pro Webcam C920 as /devices/pci0000:00/0000:00:14.0/usb3/3-1/3-1:1.0/input/input37 [6734968.751553] xhci_hcd 0000:00:14.0: >WARN Event TRB for slot 10 ep 0 with no TDs queued?
中核部分はこんな感じ
////////////////////////////////////
// O P E N D e v i c e //)
////////////////////////////////////
camFd = open(devName, O_RDWR);
if(camFd == -1){
fprintf(stderr, "Device(%s) open failed\n", devName);
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto threadExit;
}
// setup resolution etc
memset((void *)&fmt, 0x00, sizeof(fmt));
fmt.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
fmt.fmt.pix.width = startParm->width;
fmt.fmt.pix.height = startParm->height;
fmt.fmt.pix.pixelformat = V4L2_PIX_FMT_MJPEG;
ret = xioctl(camFd, VIDIOC_S_FMT, &fmt);
if(ret < 0){
fprintf(stderr, "Settup failed\n");
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
if(fmt.fmt.pix.pixelformat != V4L2_PIX_FMT_MJPEG){
fprintf(stderr, "WARNING!! Assigned incorrect fmt:%d resolition:%dx%d\n",
(int)fmt.fmt.pix.pixelformat,
(int)fmt.fmt.pix.width,
(int)fmt.fmt.pix.height);
}
///////////////////////////////////
// memory mapping
///////////////////////////////////
// request mmap
memset((void*)&req, 0x00, sizeof(req));
req.count = MMAP_CNT;
req.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
req.memory = V4L2_MEMORY_MMAP;
ret = ioctl(camFd, VIDIOC_REQBUFS, &req);
if(ret < 0){
fprintf(stderr, "VIDIOC_REQBUFS failed\n");
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
if(req.count != MMAP_CNT){
fprintf(stderr, "mmap allocate failed(%d)\n", req.count);
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
// map to userland)
for(i=0;i < MMAP_CNT;i++){
memset((void*)&buf, 0x00, sizeof(buf));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
buf.memory = V4L2_MEMORY_MMAP;
buf.index = i;
ret = xioctl(camFd, VIDIOC_QUERYBUF, &buf);
if(ret < 0){
fprintf(stderr, "mmap VIDIOC_QUERYBUF[%d]\n", i);
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
mmap_p[i] = mmap(NULL, buf.length, PROT_READ, MAP_SHARED, camFd, buf.m.offset);
if(mmap_p[i] == MAP_FAILED){
fprintf(stderr, "mmap(%d)\n", errno);
*exitStatus = (int)FWCAMCAPT_DEVERR;
gExecuted = 0;
goto closeExit;
}
mmap_l[i] = buf.length;
#if 1
fprintf(stderr, "mmbuff[%d] length is \"%u\"\n", i, buf.length);
#endif
}
// Queueing before
for(i=0;i < MMAP_CNT;i++){
memset((void*)&buf, 0x00, sizeof(buf));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
buf.memory = V4L2_MEMORY_MMAP;
buf.index = i;
ret = xioctl(camFd, VIDIOC_QBUF, &buf);
if(ret < 0){
fprintf(stderr, "VIDIOC_QBUF error\n");
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
}
////
// start stream
////
type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
ret = xioctl(camFd, VIDIOC_STREAMON, &type);
if(ret < 0){
fprintf(stderr, "VIDIOC_STREAMON error:%d\n", ret * -1);
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
// Capture Stanby
startParm->stanby = 1;
//
while(gExecuted){
fd_set fds;
FD_ZERO(&fds);
FD_SET(camFd, &fds);
struct timeval timeOut;
timeOut.tv_sec = 0;
timeOut.tv_usec = USEC_1MSEC;
ret = select(camFd + 1, &fds, NULL, NULL, &timeOut);
if(ret < 0){
if(errno == EINTR)
continue;
fprintf(stderr, "select() error\n");
*exitStatus = (int)FWCAMCAPT_OTHER;
break;
}
if(FD_ISSET(camFd, &fds)){
memset(&buf, 0, sizeof(buf));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
buf.memory = V4L2_MEMORY_MMAP;
ret = xioctl(camFd, VIDIOC_DQBUF, &buf);
if(ret < 0){
fprintf(stderr, "VIDIOC_DQBUFi error\n");
*exitStatus = (int)FWCAMCAPT_OTHER;
break;
}
if(pthread_mutex_lock(&(startParm->bufMutex)) == 0){
memcpy(startParm->frameBuff, mmap_p[buf.index], buf.bytes[6734110.675010] usbhid 3-2:1.0: >couldn't find an input interrupt endpoint
used);
startParm->length = buf.bytesused;
pthread_mutex_unlock(&(startParm->bufMutex));
}
ret = xioctl(camFd, VIDIOC_QBUF, &buf);
if(ret < 0){
fprintf(stderr, "VIDIOC_QBUF error\n");
*exitStatus = (int)FWCAMCAPT_OTHER;
break;
}
}
#if 0
else
fprintf(stderr, "TO\n");
#endif
}
////
// stop stream
////
type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
ret = xioctl(camFd, VIDIOC_STREAMOFF, &type);
if(ret < 0){
fprintf(stderr, "VIDIOC_STREAMOFF error:%d\n", ret * -1);
*exitStatus = (int)FWCAMCAPT_DEVERR;
goto closeExit;
}
////////////////////////////////////
// C L O S E D e v i c e //
////////////////////////////////////
closeExit:
close(camFd);
これを説明していくと、基本的にこの中核処理はサブスレッドで動いていて、
カメラからMJPEGのフレームが来たら
startParm->frameBuff
にコピーしてるってわけです。
ここを適当なタイミング(1秒毎とか)覗いてフレームが
あったら(ここには書いてないけど)xxx.jpegという名前で書いてます
※ここでの書き込みと、フレームデータの参照が重ならないように
mutex()してます
それと、コードの中で
camFd = open(devName, O_RDWR);
ってのがあります。
最初、カメラからビデオを読むだけだからO_RDONLYで良いと浅はかに考えていたけど、
よく考えてみたらカメラデバイスをコントロールするため、ioctl()で制御してるんだから
書き込みがいるんだよね。
ちなみに
xioctl()
はアットマークテクノさんのページ
を参考にしました(全体的にも参考にしてます)
内容的には以下のコード
//////////////////////////////////////////////////////////
// xioctl copy from
// http://manual.atmark-techno.com/armadillo-810/armadillo-810_product_manual_ja-1.3.0/ch14.html
/////////////////////////////////////////////////////////
static int xioctl(int fd, int request, void *arg){
int ret;
for(; ; ){
ret = ioctl(fd, request, arg);
if(ret < 0){
if(errno == EINTR)
continue;
return -errno;
}
break;
}
return 0;
}
メモリマップとユーザーランドのやりとりの低レベル
(っていうかioctl()とかしてる段階で感じるけど)な感じが
オタク心をくすぐるか?